http://debug-sai.blogbus.com/logs/51711788.html
asmlinkage ssize_t sys_read(unsigned int fd, char __user * buf, size_t count)
{
//傳入文件fd
struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
//根據文件fd得到file
file = fget_light(fd, &fput_needed);
if (file) {
//讀出當前偏移
loff_t pos = file_pos_read(file);
//從當前偏移讀,pos返回讀取後的偏移
ret = vfs_read(file, buf, count, &pos);
//設置新偏移
file_pos_write(file, pos);
fput_light(file, fput_needed);//
}
return ret;
}
看看fget_light是怎麼根據fd得到file的
struct file *fget_light(unsigned int fd, int *fput_needed)
{
struct file *file;
struct files_struct *files = current->files;
*fput_needed = 0;
if (likely((atomic_read(&files->count) == 1))) {
//若已經打開了
file = fcheck_files(files, fd);
} else {
//若沒有打開,加鎖
rcu_read_lock();
file = fcheck_files(files, fd);
if (file) {
if (atomic_long_inc_not_zero(&file->f_count))
*fput_needed = 1;
else
/* Didn't get the reference, someone's freed */
file = NULL;
}
rcu_read_unlock();
}
return file;
fput_light的流程如下,具體見源代碼:
fput_light->fput(當所有釋放完時還要調用__fput)
接著看 vfs_read:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
//下面都是一系列驗證
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!file->f_op || (!file->f_op->read && !file->f_op->aio_read))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count);
if (ret >= 0) {
count = ret;
if (file->f_op->read)
//一般都是到這裡調用vfs的read
ret = file->f_op->read(file, buf, count, pos);
else
ret = do_sync_read(file, buf, count, pos);
if (ret > 0) {
fsnotify_access(file->f_path.dentry);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}
跟著就是vfs設置的read函數了,對於ext2來說是
const struct file_operations ext2_file_operations = {
.llseek = generic_file_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = generic_file_aio_write,
.unlocked_ioctl = ext2_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext2_compat_ioctl,
#endif
.mmap = generic_file_mmap,
.open = generic_file_open,
.release = ext2_release_file,
.fsync = ext2_sync_file,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
};
所以是do_sync_read:
ssize_t do_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
ssize_t ret;
//初始化kiocb
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
kiocb.ki_left = len;
for (;;) {
//其實就是變了個參數傳到generic_file_aio_read中。。。具體分析就先到這了
ret = filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos);
if (ret != -EIOCBRETRY)
break;
wait_on_retry_sync_kiocb(&kiocb);
}
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&kiocb);
*ppos = kiocb.ki_pos;
return ret;
}
2013年8月11日 星期日
2013年8月9日 星期五
[review] Brownfield Application Development in .NET
說在前頭,這是一本好書,還有我不懂C#, .NET XD
簡而言之,作者相信,好的軟體流程跟設計是一切的根本,如果專案失控,大致上是這兩方面出問題,所以一書分成兩個部分,第一部分先談到brownfield application的定義,跟著提出軟體流程的工具,比方說VCS、Testing、Defect...等等,如何使用,第二部分則是設計模式跟原則,基本上遵循design pattern的兩句話,low coupling high cohesion & design for interface。
衍生出來的就很多,比方說IoC、DI...,書中主要反應在兩種設計方式上,一個是MVP,另外一個是Anticorruption layer
Anticorruption layer
 因應第三方元件或者其他需求,在每一層可以考慮加入一個layer,發揮類似seam的作用,讓上下層依賴這個介面,也就是Robert C. Martin所謂的
因應第三方元件或者其他需求,在每一層可以考慮加入一個layer,發揮類似seam的作用,讓上下層依賴這個介面,也就是Robert C. Martin所謂的
High-level modules should not depend upon low-level modules. Both should depend upon abstractions.
Abstractions should not depend upon details. Details should depend upon abstractions.
每一層可以獨立作業,也不會類似過去TCP/IP的設計方式,每一層依賴於下一層,每一層都可以獨立發展
效果類似於下圖
 圖片中綠色的區塊相當等於seam的部分SpellChecker跟SpellCheckDictionary可以分開獨立發展,中間接合的部分,由ISpellCheckDictionary承擔,有MVP的味道
圖片中綠色的區塊相當等於seam的部分SpellChecker跟SpellCheckDictionary可以分開獨立發展,中間接合的部分,由ISpellCheckDictionary承擔,有MVP的味道
簡而言之,作者相信,好的軟體流程跟設計是一切的根本,如果專案失控,大致上是這兩方面出問題,所以一書分成兩個部分,第一部分先談到brownfield application的定義,跟著提出軟體流程的工具,比方說VCS、Testing、Defect...等等,如何使用,第二部分則是設計模式跟原則,基本上遵循design pattern的兩句話,low coupling high cohesion & design for interface。
衍生出來的就很多,比方說IoC、DI...,書中主要反應在兩種設計方式上,一個是MVP,另外一個是Anticorruption layer
Anticorruption layer

High-level modules should not depend upon low-level modules. Both should depend upon abstractions.
Abstractions should not depend upon details. Details should depend upon abstractions.
每一層可以獨立作業,也不會類似過去TCP/IP的設計方式,每一層依賴於下一層,每一層都可以獨立發展
效果類似於下圖

2013年8月4日 星期日
javascript loading的考量
javascript loading有些必須考量的點,比方載入方式、相依性、模組化、最佳化
2. 使用document.write方式動態載入
3. 自行產生DOM元素加入
4. 使用AJAX動態取得
現在web browser通常使用aysnchronous載入,最佳化性能,但是有時必須考慮相依性
參考資料:
https://developers.google.com/closure/compiler/?hl=zh-TW
http://josephj.com/entry.php?id=349
http://www.jb51.net/article/17992.htm
http://ithelp.ithome.com.tw/question/10120521?tag=rss.qu
http://tc.itkee.com/developer/detail-1a9a.html
http://www.puritys.me/docs-blog/article-160
方式
1. 直接使用script tag的src屬性2. 使用document.write方式動態載入
3. 自行產生DOM元素加入
4. 使用AJAX動態取得
現在web browser通常使用aysnchronous載入,最佳化性能,但是有時必須考慮相依性
相依性
javascript loading相依性上有RequireJS來處理,一來可以解決相依性,二來可以只載入必要的元素即可模組化
而引入的javascript通常可以視為一個模組,一個好的模組必須符合一些規範,如AMD,而CommonJS正是這樣的概念下的RIA framework最佳化
而javascript載入有時取決於script tag的位置,變數名稱以及檔案形式。好比將tag至於文件尾端,讓DOM Tree儘快生成,產生頁面,但是副作用是有時script產生的動態元素會比較慢呈現在網頁上。為了讓javascript parser比較快讀取產生,使用如google closure compiler,縮短變數名稱等等動作,可以讓javascript產生較好的效能,但是會犧牲程式的可讀性參考資料:
https://developers.google.com/closure/compiler/?hl=zh-TW
http://josephj.com/entry.php?id=349
http://www.jb51.net/article/17992.htm
http://ithelp.ithome.com.tw/question/10120521?tag=rss.qu
http://tc.itkee.com/developer/detail-1a9a.html
http://www.puritys.me/docs-blog/article-160
2013年8月1日 星期四
[review] MVP
之前在網路上搜尋MVP的時候,無意看到有人說MVC更適合web application這種stateless的開發,非常違反我直覺地描述,最近終於發現可能得出處,是一本書
Brownfield Application Development in .NET,中文翻譯:軟體構築美學
先說違反直覺的部分,首先MVC提出非常早,遠早於現在流行的web application,也就是說MVC一開始是為了application設計才對,以這種觀點,application大多屬於有狀態的(state),很少是stateless
作者有幾點小小的誤會,首先MVC架構定義跟傳統不大一樣,可以參考POSA一書對MVC架構的描述,MVP不是Martin Folwer提出來的,首先是由IBM於1997年左右提出的,Martin Folwer的MVP算是IBM的改良版本,這種誤解有點類似Martin Folwer提出了refactoring的概念是一樣的,不過Martin Folwer是一個總結並且發揚光大的人是肯定的,非原本名詞的提出者,一點都不損及Martin Folwer的地位
撇開這個不講,書中對各種模型的描述倒是很清楚,如Passive View、Supervising Controller、MVC、MVP
為了觀察web application,先考慮過去MVC是由誰驅動?大多是由應用程式建立了一堆view之後,再由view引發事件驅動controller,可是在web appliction,卻是由網頁直接接觸controller,然後再產生新的view(網頁)

因為stateless以及web流程的特性,controller變成了進入點,再加上route的概念盛行,controller工作變成了,如何引導流程,且非由view創立出來的,所以整體的角色改變了
再者MVC本身有個小小的缺點,view本身是認知model的存在(耦合性),這有一點點暴露風險的部分是,程式設計師會直接透過view去操作model,而非controller,此外view往往為了model必須要修改,無法獨力發展
MVP有效的解決這問題,首先view直接獨立發展,畫面更新等等事情交由presenter去考慮,model本身從前就已經很獨立了,現在更加地不用透過類似observer patter去通知view,耦合更少。在view與model都獨立的狀況下,必須有角色負責媒合兩者,那個就是presenter,而presenter必須利用IoC的概念,引入兩者view跟model(有可能有很多view與很多model instances),作為媒介
 可是這時候,一些事件的傳遞要如何作用?在web application上面,這件事情不是很嚴重,因為server直接扮演了controller以及route腳色,如同第一個MVC圖片一樣,只是現在將MVC中的MV改成了MVP,但是在應用程式上呢?所以才有上面的application controller存在。
可是這時候,一些事件的傳遞要如何作用?在web application上面,這件事情不是很嚴重,因為server直接扮演了controller以及route腳色,如同第一個MVC圖片一樣,只是現在將MVC中的MV改成了MVP,但是在應用程式上呢?所以才有上面的application controller存在。
這裡可能會冒出的疑問是,那麼model跟view之間的耦合性不見了,那麼如何更新view?由presenter,但是presenter也無法知道model有沒有更新阿!?Martin Folwer告訴我們,如果要達到主動更新只好把類似observer pattern再放到model跟presenter身上,耦合性又回來了XD天下沒有白吃的午餐,不過透過MVP,讓view與model可以獨立發展,大大提高view的resue了
Brownfield Application Development in .NET,中文翻譯:軟體構築美學
先說違反直覺的部分,首先MVC提出非常早,遠早於現在流行的web application,也就是說MVC一開始是為了application設計才對,以這種觀點,application大多屬於有狀態的(state),很少是stateless
作者有幾點小小的誤會,首先MVC架構定義跟傳統不大一樣,可以參考POSA一書對MVC架構的描述,MVP不是Martin Folwer提出來的,首先是由IBM於1997年左右提出的,Martin Folwer的MVP算是IBM的改良版本,這種誤解有點類似Martin Folwer提出了refactoring的概念是一樣的,不過Martin Folwer是一個總結並且發揚光大的人是肯定的,非原本名詞的提出者,一點都不損及Martin Folwer的地位
撇開這個不講,書中對各種模型的描述倒是很清楚,如Passive View、Supervising Controller、MVC、MVP
為了觀察web application,先考慮過去MVC是由誰驅動?大多是由應用程式建立了一堆view之後,再由view引發事件驅動controller,可是在web appliction,卻是由網頁直接接觸controller,然後再產生新的view(網頁)

因為stateless以及web流程的特性,controller變成了進入點,再加上route的概念盛行,controller工作變成了,如何引導流程,且非由view創立出來的,所以整體的角色改變了
再者MVC本身有個小小的缺點,view本身是認知model的存在(耦合性),這有一點點暴露風險的部分是,程式設計師會直接透過view去操作model,而非controller,此外view往往為了model必須要修改,無法獨力發展
MVP有效的解決這問題,首先view直接獨立發展,畫面更新等等事情交由presenter去考慮,model本身從前就已經很獨立了,現在更加地不用透過類似observer patter去通知view,耦合更少。在view與model都獨立的狀況下,必須有角色負責媒合兩者,那個就是presenter,而presenter必須利用IoC的概念,引入兩者view跟model(有可能有很多view與很多model instances),作為媒介
這裡可能會冒出的疑問是,那麼model跟view之間的耦合性不見了,那麼如何更新view?由presenter,但是presenter也無法知道model有沒有更新阿!?Martin Folwer告訴我們,如果要達到主動更新只好把類似observer pattern再放到model跟presenter身上,耦合性又回來了XD天下沒有白吃的午餐,不過透過MVP,讓view與model可以獨立發展,大大提高view的resue了
2013年7月21日 星期日
[review] MVC與MVP
MVC基本職責
- Model : 提供商業邏輯功能、知會view狀態改變
- Controller : 接受輸入、事件,驅動model
- View : 呈現資料,連結Controller,乃至於提供互動介面
有個有點問題的MVC用於動態網頁的設計圖

在過去application實作方式,大多使得view直接認得model,但是model只是透過observer model通知view改變,藉以解構model跟view之間的耦合
所以即使到了動態網頁,應該也不全都是透過controller傳遞scalar data而應該是傳遞model的object
借用下面的圖片說明MVC model的一種life time流程,傳統GUI元件往往把view跟controller連結再一起,所以controller由view建立,事件也由view發起
.gif)
MVP
上面是在於單機application的時候,往往model會存在記憶體中相當的時間,但是到了web application時代,因為每次請求都是一個新的狀態,換句話說就是stateless,元件的功能側重的變化是- Model : 提供商業邏輯功能、保存資料、
知會view狀態改變 - Controller : 接受請求,驅動model,控制流程
- View : 呈現資料,連結Controller,乃至於提供互動介面
重點在web模式下發生變化的model不是持續、有狀態(stateless)的存在,也就是沒有必要去通知view更新,也辦不到。controller變得接受請求,而比較不像是事件驅動,view由html取代,與controller的連結性以及互動也變得稀薄
由於應用場景的不同,使得MVC這個架構並不是很適合,而產生了新的變形

因為是stateless,所以每次請求都類似service,controller需要分配協調的功能性變弱。這設計模式進一步想解開model/view之間的耦合,連observer pattern都想擺脫掉,另外引入了matrin folwer的IoC思維
- View : 呈現資料以及對presenter提出請求
- Presenter : 提供services,只有特定的介面,所以view要建立合乎presenter的介面 (IoC)
- Model : 照舊XD,但是完全不必再去通知view
這樣的設計好或不好要看場合,由於拿掉了observer pattern,model的改變在web應用上很沒有問題,因為model是被動的,並不用及時通知前端(view)改變。所以在win form上面的設計model有時是跟presenter上是雙向溝通的,可以讓model通知presenter,進而更新view,這點在martin folwer的supervising controller上也有提到
有趣的是,這樣的想法比較接近一開始的圖,所以我說那張MVC的圖有問題XD
參考資料:
一個做得不錯的MVC投影片
Backbones.js
http://documentcloud.github.io/backbone
MVP實作參考
http://www.cnblogs.com/leoo2sk/archive/2010/01/28/mvp-in-practice-based-on-dot-net.html
2013年7月18日 星期四


[Review] PHP Tools
壓力測試
- ApacheBench (ab)
- JMeter
- Siege
記得把防火牆關閉,類似DoS的動作會因為防火牆而失敗
快取
pecl install apc記得在php.ini內加入extension=apc.so
Profiling
XHProf,來自facebook常用的好工具程式分析工具
- phploc
- phpcpd/phpmd,找出php code重複的地方,找出bad smell
- phpcs,一種是否合乎某種規格的探測器,比方是否遵循某種命名法則、有無comment
- phpdoc/php-apigen,文件產生器
測試
- PHPUnit (單元測試/unit test)
- Behat/PHPSpec (行為測試/behavior test)
- Selenium (系統測試)
版本控制工具
- SVN
- GIT
- Phing,deploy工具
MVC framework
直接參考這邊吧http://jonathanmh.com/best-php-mvc-frameworks-of-2013/有陣子沒玩PHP了,最近review了一下,順手紀錄了一下
2013年7月14日 星期日
GRASP General Responsibility Assignment Software Patterns
這是回顧Applying UML and Patterns一書(chapter 16 or 17?)上面提到的設計原則
- information expert
- creator
- high cohesion
- low coupling
- controller
Q. 誰該被分配某個operations?
A. information expert提示將operation交付予擁有資訊的類別,也就是賦予相對應的責任,哪個內別有資訊,便應當負起處理該資訊的任務
Q. 誰該建立某類的物件?
A. creator告訴我們擁有下列狀況的腳色或許應處理
- B聚合(aggregate)有 A
- B包含(contain)A
- B record A
- B closely use A
- B have initialization information of A
Q. 將某個方法或者屬性分配給...
A. low coupling是個好的選擇,提升coupling儘量避免,除非他們的關聯性是必要的
Q. 如何保持複雜度在一定程度內?
A. high cohesion,適當的模組化,避免使得物件之間的互動很難理解、很難維護、很難reuse
Q. 誰該處理系統輸入事件? (metaphor)
A. 將處理訊息的責任指派給兩種概念的類別:
- 代表整個系統或者子系統
- 代表系統事件所屬的使用者情節
最後該說的,如同作者提到的CRC (class reponsibility collaborator cards)卡是個好工具
參考資料
2013年7月10日 星期三
Unit Test的好文章
雖然使用的是C#的程式語言,但是不懂應該不妨礙閱讀才是,只要學過一些OOP
http://www.dotblogs.com.tw/hatelove/archive/2012/11/05/learning-tdd-in-30-days-day2-unit-testing-introduction.aspx
上面連結說明了為何、如何使用unit test
看過之後,有個想法,如何對程序語言進行如unit test的動作,雖然C這種程序語言是不支援OO,但是如果導入unit test精神以及實作其技術(不是只有unittest class還包含類似mock, stub ...之類的)
http://www.dotblogs.com.tw/hatelove/archive/2012/11/05/learning-tdd-in-30-days-day2-unit-testing-introduction.aspx
上面連結說明了為何、如何使用unit test
看過之後,有個想法,如何對程序語言進行如unit test的動作,雖然C這種程序語言是不支援OO,但是如果導入unit test精神以及實作其技術(不是只有unittest class還包含類似mock, stub ...之類的)
2013年7月9日 星期二
OO的"沉重",DDD的反思
DDD是乎達成了相當了不起的成就,給出了一套方法論,讓programmer可以沿著物件導向開發的方式前進,一切的問題似乎是迎刃而解!?
但是本身的經歷說明了似乎還有長遠的路要走,下面記錄下我幾個不解之處
不過在DDD內,並沒有詳細探討到DB模型如何融入到domain model內,倒是Jimmy Nilsson的著作談到,如果我們想把Persistence機制與OO模型完全切開,將會導致七八種很嚴重的"後遺症",然則讓OO model與Persistence機制完全分開又有其好處,不過看來現實是極難辦到
其他典範如SOA、generic programming、Aspect...等等,都是一些很好的考量,我們看到compiler愈來愈強大,如何混合這些方法論或者技術層次的工具,都是一些開發時可以考量的。如Modern C++ design一書結合pattern以及generic programming的技巧就叫人拍案叫絕,但是個人認為這種技術的門檻太高,短時間內不會被廣泛採用。Aspect則是似乎可以解決Persistence以及OO model分割的問題
但是本身的經歷說明了似乎還有長遠的路要走,下面記錄下我幾個不解之處
database/persistence是否屬於domain model??
這個大哉問其實再Martin Folwer的PoEAA有所解答,本書主要討論DB模組與OO模型之間轉換的問題,根據作者的講法,是的DB物件屬於domain model的一部分,同時hibernate可能也是實作了大多數PoEAA裡面的內容不過在DDD內,並沒有詳細探討到DB模型如何融入到domain model內,倒是Jimmy Nilsson的著作談到,如果我們想把Persistence機制與OO模型完全切開,將會導致七八種很嚴重的"後遺症",然則讓OO model與Persistence機制完全分開又有其好處,不過看來現實是極難辦到
DDD的實際範例?
單單DDD一本書,實際上有太多縫隙需要填補,Jimmy Nisson的著作是個不錯的選項,然則還是有許多方面需要考慮的DDD是否為唯一方式?是否與其他模範(paradigm)設計方式結合?
前者顯然否定,明顯來說一些嵌入式系統底層就無法享受這樣的好處,不過物件導向的原則倒是往往深入開發的過程。其他典範如SOA、generic programming、Aspect...等等,都是一些很好的考量,我們看到compiler愈來愈強大,如何混合這些方法論或者技術層次的工具,都是一些開發時可以考量的。如Modern C++ design一書結合pattern以及generic programming的技巧就叫人拍案叫絕,但是個人認為這種技術的門檻太高,短時間內不會被廣泛採用。Aspect則是似乎可以解決Persistence以及OO model分割的問題
OO的"沉重",DDD (3)
此書最後的部分,也是最精彩跟抽象的部分,從單一專案開發跨足多專案開發


作者再某一章節給出了顯示完整性、精鍊以及大比例原則之間的互動,同時顯示了一個範例如何借助DDD所有技巧發展出一個domain model
作者首先點出,一個大企業,裡面維護單一的專案是不可能的,也就是累積了或者同時會有好幾個專案在開發,也不是所有專案都使用OO或者DDD開發,也就是多種的可能性
然則使用Domain model,可以嘗試著去描述其他的部分,也就是domain model的本質上並不受限於任何程式語言風格,講求的是溝通以及理解
在整合的過程中,有三件事情是重要的
- 一致性以及完整性 : 所有開發團隊對於相關的部分必須有一致的認知,否則會造成一些整合上不可預期的結果
- 精煉 : 為了能夠掌握專案的目標,同時維護專案在可以理解的情況下,精煉、精簡出Core domain有其必要性
- 大比例架構 : 所有事情不是一步登天,做為指導原則作者提倡大比例架構,如果特殊化,在軟體上可以稱為Architecture
一致性以及完整性
一張圖道盡整個一致性以及完整性維護的地圖

Bounded Context : 將想要表達的模型,有範圍的規劃起來,並且給予有意義的名字,同時確保範圍內不會受到其他模型的影響。
Continuous Integration : 分布整合、自動測試、概念整合、model整合,尤其是自動測試,是一種快速檢視Context之間有沒有問題的技術
Context Map : 強調各bounded context之間的交互作用,可以思考SOA是如何運作
由上面三個主要元素,可以知道,在畫分完畢後,主要的問題將是context之間的介面
最常見的是介面/service之間的問題,是否由相同團隊開發?是否有權利要求提供介面?是否需要完成自己轉接介面(adapter),而影響因素有溝通能力以及決定權
Shared Kernel : 共享的概念上子集,類似binary/source code等級的分享
Customer/Supplier Development Team : 上下游關係,如開發廠仰賴系統廠的功能,有分層的味道,兩邊必須要有適當的協調者
Conformist : 單純的跟隨者,例如開發廠完全無法要求系統廠提供任何支援性功能,那只有單純的跟隨
Anticorruption Layer : 透過實現特定層面(layer),團隊自行完成上游所不提供,但自己所需的功能
Open Host Service : 經過一段時間開發,整合所有開放的service
Published Language : 透過一種標準,開放service,如SOAP
兩大因素與採用模式的關係圖如下

精煉
為了能夠集中精神在主要目標,以及提供能夠處理的內容,深入理解context之後,精煉出主要的模型是必須的,但也是費力氣的
Domain Vision Statement : 願景是很簡短且重要的
Highlighted Core : 從大量的背景知識中抽出重要的部分
Segregated Core : 將核心更加模組化
Generic Subdomain : 將支持性的模型移出core domain
Cohesive Mechanism : 讓domain集中在what to do不是耗費在解釋how to do
Abstract Core : 抽象畫主要設計
其中作者點出了很多的風險
其中作者點出了很多的風險
大比例原則
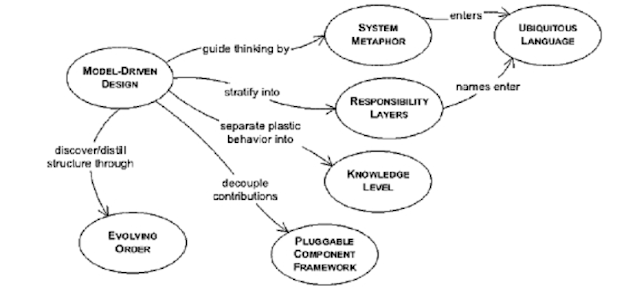
以architecture角度切入會顯得比較容易體會,但是architecture並不等於domain model,所以作者提供的觀點卻是更高階的

- evolving order : 概念上的模型必須隨著模型一直演變
- system metaphor : 適當的使用隱喻可以增加對系統的了解,比方說再architecture上說明是MVC
- responsibility layers : 模型對象往往已職責為依歸,仔細觀察這些對象的變化頻率以及職責所在,可以適當的aggregate以及module化
- knowledge level : 如果抽象對象之間的關係限制,無法完整描述,則應把限制這樣的知識暴露到domain model之中,作者舉例出,兩個物件,員工以及退休計畫,如果只有兩個對象,可以隨意匹配,然而某些員工只能享有某些退休計畫,所以把"員工種類的退休計畫"這個對象放入domain model來滿足
- Pluggable component framework : 從interface以及interaction中抽出abstract core的部份,並且建立一個框架,符合介面的元件都可以被抽換
作者再某一章節給出了顯示完整性、精鍊以及大比例原則之間的互動,同時顯示了一個範例如何借助DDD所有技巧發展出一個domain model
2013年7月1日 星期一
OO的"沉重",DDD (2)
在軟體開發過程,每個iteration一般會不斷添加新的需求,導致domain model不斷的變化,而軟體工程師以及領域專家,對於domain model也會更了解,而為了避免domain model不斷膨脹到無法處理,人們會發揮抽象、精練的能力
作者提出了deep model以及supple design的設計,所謂deep model也就是更加抽象、更容易掌握的模型,而supple design則是彈性的設計,讓模型更容易擴充,兩者都可以透過refactoring達到,很可惜,這裡refactoring不是類似code的操作方式,而是概念上的不斷重新調整
Deep Model
在討論domain model上有幾個重要的概念,可以幫助程式設計師,找出更恰當的模型或者修正一些模型的問題
在此作者提出了specification pattern,將依些限制或者補充,當成類似英文中的副詞的位置,有時這個元素必須要獨立出來,置於domain model,可以更加完整的描述整個模型
Supple Design
supple design的部分則是彈性的設計,然則會有overengineering的疑慮,導致過度的設計,然則一個最大的原則是low coupling high cohesion,將複雜的模型用簡單的關係表示,不要過度使用抽象層面
作者也沒有完全給出一個恰如其分的設計的明確方式,更沒有檢驗的方式,不過提出了若干的pattern作為思考的方向,如下圖表示

A Declarative Style of Design
由上面幾個組合而成,則得到類似Design by Contract的效果,可以達到某些特性的限定
作者提出了deep model以及supple design的設計,所謂deep model也就是更加抽象、更容易掌握的模型,而supple design則是彈性的設計,讓模型更容易擴充,兩者都可以透過refactoring達到,很可惜,這裡refactoring不是類似code的操作方式,而是概念上的不斷重新調整
Deep Model
在討論domain model上有幾個重要的概念,可以幫助程式設計師,找出更恰當的模型或者修正一些模型的問題
- 反覆討論:確定與領域專家達成一致正確的共識,有時候領域專家會"尊重"程式設計師的設計,雖然這個設計可能跟現實不吻合,要反覆討論
- 傾聽語言:從交談過程中,確定專家是否確定這個模型與描述一致
- 找出矛盾:需求上是否有模型無法解釋處?
- 不斷學習:尋找過去經驗,或者閱讀相關書籍
- 找出implicit處:發覺應該抽出的概念,如限制、補充
在此作者提出了specification pattern,將依些限制或者補充,當成類似英文中的副詞的位置,有時這個元素必須要獨立出來,置於domain model,可以更加完整的描述整個模型
Supple Design
supple design的部分則是彈性的設計,然則會有overengineering的疑慮,導致過度的設計,然則一個最大的原則是low coupling high cohesion,將複雜的模型用簡單的關係表示,不要過度使用抽象層面
作者也沒有完全給出一個恰如其分的設計的明確方式,更沒有檢驗的方式,不過提出了若干的pattern作為思考的方向,如下圖表示

- Intention Revealing Interfaces:命名與操作時要描述他們的目的與效果,封裝物件的行為
- Side-Effect-Free Functions:盡可能地將邏輯封裝在function內,如果必要回傳考慮回傳value object,有效的控制影響層面
- Assertion:如果side-effect是implict的,大量交互作用下,結果變得無法預測,利用assertion可以減輕不可預期的效果
- Standalone Classes:極致的low coupling就是standalone class
- Closure of Operations:運作後回傳相同型態,可以降低依賴程度
- Conceptual Contours:找出輪廓,避免關係太複雜,也避免介面無法解釋。設計得太粗糙則介面無法解釋模型,關係太複雜則是呈現了太多的細節。
A Declarative Style of Design
由上面幾個組合而成,則得到類似Design by Contract的效果,可以達到某些特性的限定
- Acceptable and unacceptable input values or types, and their meanings
- Return values or types, and their meanings
- Error and exception condition values or types that can occur, and their meanings
- Side effects
- Preconditions
- Postconditions
- Invariants
可以更嚴格的保證行為以及其結果
2013年6月29日 星期六
OO的"沉重",DDD (1)
Domain Driven Design提示了我許多以前沒看過的議題,如何讓設計者更加專心地在OO上面
Domain model是一種Ubiquitous lanuage
為何不如XP之類的agile process採用user story之類的技巧呢?主要的問題在於各個user story以及design存在於設計師的心中,是一種隱性的資料(implicit data),其次agile process,往往產出的主要成果是code,code是一種完美的實現(implemetation)的呈現,然則是太細節,如果將專案的整個class diagram畫在黑板上鐵定很壯觀,但是恐怕解釋要花上很久
而如同agile process一樣,必須發展適當的、共通的語言,將設計精簡的呈現出來,且DDD和agile process一樣相信,feedback是很重要的,設計過程必須和使用者溝通,也就是"語言"主要的用途
如何從問題/需求過渡到設計,DDD的方式採用了類似DB Table design(這是一個很不好的比喻,但是退化/極簡的domain model幾乎就是這種模式),跟著利用design pattern作為指引,可以簡單地使用下面的圖形作為依據

設計工作主要圍繞著service、entity、value object之間的設計
而entity以及value object中間往往有關係,在設計上,希望關係(關係在設計圖上用連線表示)愈簡單愈好,避免太過複雜的關係,簡化關係的方式有三

另外一種"打包"關係的方式就是使用aggregation,將物件打包成一個entity,所有內部資料必須透過root處理,且參考到的物件,往往只是value object,也就是並不會影響到實際物件內部物件的狀態

同樣的,如果需要生成狀態的抽象畫,可以使用factory pattern。而repository pattern則適用於查詢相似物件的應用或者封裝travel/filter的行為,比方說,從persistence裝置找到所有大於65歲的老年人口,如果要從某個根物件訪問到所有符合條件的物件太過費時、複雜且沒效率。
DDD有兩個特色,全都形而上,幾乎不涉及persistence,也不涉及class定義等等的部分(GoF多少有class定義)。DDD提示我們如何專注在OOAD上面,而非過去的設計模式(procedure or others)
這裡有些anti-pattern,可供參考,是否是使用舊的方式在設計
經過這些基本考量之後,跟著在每個iteration,如何繼續改善domain model,是一個重要的工作,而且沒有固定的方法
Domain model是一種Ubiquitous lanuage
- 現實以及模型做綁定,這是很簡單的規則,但是往往愈到專案後期,分析的模型愈是和實際的程式碼相差愈大
- Domain Model不是單純的圖形,他是一種語言,也就是包含了上下文(context)
- Domain Model因為有語言的特色,大家需要看得懂,聽得懂
- Domain Model必須不斷的精練,也就是隨著專案成長以及精簡
為何不如XP之類的agile process採用user story之類的技巧呢?主要的問題在於各個user story以及design存在於設計師的心中,是一種隱性的資料(implicit data),其次agile process,往往產出的主要成果是code,code是一種完美的實現(implemetation)的呈現,然則是太細節,如果將專案的整個class diagram畫在黑板上鐵定很壯觀,但是恐怕解釋要花上很久
而如同agile process一樣,必須發展適當的、共通的語言,將設計精簡的呈現出來,且DDD和agile process一樣相信,feedback是很重要的,設計過程必須和使用者溝通,也就是"語言"主要的用途
如何從問題/需求過渡到設計,DDD的方式採用了類似DB Table design(這是一個很不好的比喻,但是退化/極簡的domain model幾乎就是這種模式),跟著利用design pattern作為指引,可以簡單地使用下面的圖形作為依據

設計工作主要圍繞著service、entity、value object之間的設計
- entity含有唯一ID,且生命週期間狀態的轉換是有意義的,如身分證
- value object則是臨時的狀態,通常是依附於entity上面
- service則是一種類似於基礎建設的存在,往往處於領域的邊界,如DNS service
而entity以及value object中間往往有關係,在設計上,希望關係(關係在設計圖上用連線表示)愈簡單愈好,避免太過複雜的關係,簡化關係的方式有三
- 限定travel方向
- 限定關聯方式
- 減少關聯


同樣的,如果需要生成狀態的抽象畫,可以使用factory pattern。而repository pattern則適用於查詢相似物件的應用或者封裝travel/filter的行為,比方說,從persistence裝置找到所有大於65歲的老年人口,如果要從某個根物件訪問到所有符合條件的物件太過費時、複雜且沒效率。
DDD有兩個特色,全都形而上,幾乎不涉及persistence,也不涉及class定義等等的部分(GoF多少有class定義)。DDD提示我們如何專注在OOAD上面,而非過去的設計模式(procedure or others)
這裡有些anti-pattern,可供參考,是否是使用舊的方式在設計
- 每個entity就是對應一個table或者一個record
- 關係非常複雜,很多關係是雙向的
- 所有物件的persistence是由一個巨大的facade對應到DB或者檔案
經過這些基本考量之後,跟著在每個iteration,如何繼續改善domain model,是一個重要的工作,而且沒有固定的方法
OO的"沉重",architecture design(架構設計)
初步建立
從需求捕捉=>分析=>設計=>code,由OOAD到OOP是一件不簡單的工作,從UP來說,可能的流程是這樣的
中間過程
建構架構
從需求捕捉=>分析=>設計=>code,由OOAD到OOP是一件不簡單的工作,從UP來說,可能的流程是這樣的
Use cases=>analysis model=>design model=>code
如果簡單的說,就是找出需求,分析的時候分離出名詞跟動詞,將其組合成物件,跟著抽象化倒出analysis model,借用design pattern設計出模型,最後寫出程式碼
中間過程
似乎很簡單,但是中間很多空隙(gap)需要填充,比方說UP推崇architecture centric的思維,那麼如何找出architecture?這是一個很困難的工作
為了設計architecture,UP擴展了許多東西,首先他們在use cases內部添加了一些constraints,表達non-functional features,比方fault tolerance、performance ...,這些非功能性的限制,跟著引入了controller、boundary object以及entity組成的collaboration diagram
利用sub system interface做切割,填補design以及requirement之間的縫隙,並且完成其中的對應(tractability在CMMI很重要!)
建構架構
UP中architecture centric的設計方式有賴經驗,而且要take care的重點很多,很難一概而論,同時要考慮user centric、functional features跟non-functional features,導致作法多樣,同時為了抽象表示的不足,在UP才引入collaboration diagram
在設計architecture的時候可以考慮Matrin Folwer的建議,使用domain model,可以使用DDD (domain driven design)模式,DDD一口氣跳過分析方式,直接由需求到設計,而DDD面臨的兩個議題是,模型的描述語言以及分析的方式
在DDD的部分,使用domain model是很好的選擇,跟UP的collaboration diagram很像,然則也不是那麼容易。主要一個議題是,如何符合iterative建構?如果要辨識出所有的需求再來考慮architecture,整體就變得類似waterfall的設計方式
模型的描述語言DDD使用類似class diagram的模型,並且加上類似use case的補充來描述,客戶專家以及程式設計師,必須懂得同樣的terms,DDD模型大多時候不考慮operations,連attributes也很少紀錄,畢竟是一種抽象思考。
另外一個議題是分析的方式,DDD利用design pattern填補分析方式的不足,DDD相信大家都可經由消化知識,抽象畫原本的議題,進而達成共識(領域專家未必能接受這種語言),其次這裡的design pattern也與GoF不大一樣,主要注重抽象的層級
另外一種architecture的設計方式類似DDD,首先確立業務目標(白雲,參考writin effective use case 一書),接著確立範圍以及特色(風箏跟海平面),同時利用類似use case的上下文(context)來分割出architecture的輪廓,本質上跟DDD很類似,但是只是比較方法論去形塑domain model
不管DDD或者是使用UP的cooperation diagram,重點必須找出重要的(考慮各種non-functional feature)、主要的(risk)、使用者最關心的(user centric),來做為architecture model,如果單純依照UP提示的,找出涵蓋整個系統,一寸深的architecture,我想只有非常資深的設計師才能做到,且有太多不必要的考量因素
還缺了甚麼?
architecture相當程度是為了演繹一些系統重要的部分,形成重要的骨幹,然則與DDD/Domain model有點不大一致,Domain model主要是要表達整體的概念,而DDD則是以Domain model為依歸衍生設計
可以說architecture是Domain model的主要部分,用以檢驗是否滿足各種需求(functional and non-functional)
還缺了甚麼?
architecture相當程度是為了演繹一些系統重要的部分,形成重要的骨幹,然則與DDD/Domain model有點不大一致,Domain model主要是要表達整體的概念,而DDD則是以Domain model為依歸衍生設計
可以說architecture是Domain model的主要部分,用以檢驗是否滿足各種需求(functional and non-functional)
2013年6月26日 星期三
CMMI簡介(1)
說到CMMI,一般就是拜讀CMMI: Guidelines for process Integration and Product Imporovement這一本書
- CMMI由眾多的process組成,通過特定process之後可以達到某個Level,但是主要又以objective為主
- 每個process分成許多的objective,如果只跟該process有關的為specific goal (SG),跟整個level有關的objective列為generic goal (GG)
- 每個SG或者GG有許多practice ,分別是SP跟GP,往往跟產出的work product有關,也就是要有相關的描述
- 然則CMMI告訴大家What to do,但是沒有告訴大家How to do,所以以軟體來說,軟體工程/軟體流程/PMP是很好具體實踐的手法
- CMMI涉及組織流程的以及process的推行,這部分倒是軟體工程較少著墨,軟體流程幾乎從缺的地方
軟體測試...筆記(1)
因為教科書上面已經寫了很多,撇開測試的定義以及目的不談,單以軟體流程來說(也就是不涉及組織行為),最容易一窺全貌的是最著名的V-model或者W-model
但是從W-model來說,由於太過抽象,一般在requirement test跟functional test變得很模糊
比方說,requirement test可以執行幾樣工作的檢查
- Visible ?
- Clear? (unambiguous)
- Complete?
- Consistent? (conflicting requirements must be prioritized)
- Reasonable? (achievable)
- Measurable? (quantifiable)
- Modifiable? (will it change or is it stable?)
- Traceable? (the source is known)
- Dependent requirements identified?
- Testable? (given current environment, resources, skills)
或許可以使用specification by example的作法,再來檢驗這件事情會比較容易,也比較全面,以specification by example為骨幹,檢驗這幾個因素為分支,這樣就顯得較為明顯。
至於其他V model內建議的unit test, integrated test, system test, acceptance test比較工程化,也比較容易理解
以工程化的測試來說
依照測試特性可以分成
- 白箱測試
- 灰箱測試
- 黑箱測試
依照開發過程可以分成
- unit test
- integrated test
- system test
- acceptance test
- regression test
依照需求分類可以分成
- smoke test
- sanity test
- benchmark test
依照性質分類可以分成
- functional test
- equivalance class test
- boundary test
- random test
- state transition test
- nonfunctional test
- install/uninstall test
- usability test
- negative test
- recovery test
- security test
- compatibility test
- performance test
- stress test/load test
- volume test
- ad hoc test
在CMMI Level 3中可以對應到Verfication and Validation (V&V) KPA這個項目
Verfication : Are we building the thing right?
Validation : Are we building the right thing?
主要任務是
- 可追蹤性分析
- 評估
- 介面分析
- 關鍵性分析
- 測試
- 危害性分析
- 風險分析
- 其他
2013年5月27日 星期一
hadoop入門(1)
安裝jdk
add-apt-repository "deb http://archive.ubuntu.com/ubuntu hardy main multiverse"
add-apt-repository "deb http://archive.ubuntu.com/ubuntu hardy-updates main multiverse"
add-apt-repository "deb http://archive.canonical.com/ lucid partner"
apt-get update
apt-get install sun-java6-jdk
設定環境變數
export JAVA_HOME=
export CLASSPATH=
export PATH=
安裝ssh server
apt-get install ssh
設定key
ssh-key-gen -t dsa -P '' -f ~/.ssh
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
下載hadoop並且解開
我用的是1.2
找到WordCount範例,網路上很多,已經是hadoop基本的hello world了
編譯方式javac WordCount.java -classpath ~/hadoop-1.2.0/hadoop-core-1.2.0.jar
打包jar -cvf wordcount.jar -C wordcount/ ./
準備input檔案
echo "hello world bye world" >file01
echo "hello hadoop bye hadoop" >file02
~/hadoop/bin/hadoop dfs -mkdir input
~/hadoop/bin/hadoop dfs -put ~/file0* input
執行
~/hadoop/binhadoop wordcount.jar WordCount input output
=============
hadoop基本有兩部分dfs以及map-reducer
因為要分散式計算以及顧及到容錯,所以採取dfs
跟著map將輸入分散,然後再由reduce整合,map分散的時候輸入一組key1,value1,map運算完畢則是輸出另一組key2,value2,reduce則是根據key 2, value 2做資料整合,接著輸出key3, value3
從word count來說,key1可能是jab id或者hadoop產生的key,value則為一串文字,跟著將字串分解成單字,寫出的(key2, value2)可能是(hello,1),接著reducer收到後會把這些數值加總起來,跟著輸出(key3, value3)可能為(hello, 2)
add-apt-repository "deb http://archive.ubuntu.com/ubuntu hardy main multiverse"
add-apt-repository "deb http://archive.ubuntu.com/ubuntu hardy-updates main multiverse"
add-apt-repository "deb http://archive.canonical.com/ lucid partner"
apt-get update
apt-get install sun-java6-jdk
設定環境變數
export JAVA_HOME=
export CLASSPATH=
export PATH=
安裝ssh server
apt-get install ssh
設定key
ssh-key-gen -t dsa -P '' -f ~/.ssh
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
下載hadoop並且解開
我用的是1.2
找到WordCount範例,網路上很多,已經是hadoop基本的hello world了
編譯方式javac WordCount.java -classpath ~/hadoop-1.2.0/hadoop-core-1.2.0.jar
打包jar -cvf wordcount.jar -C wordcount/ ./
準備input檔案
echo "hello world bye world" >file01
echo "hello hadoop bye hadoop" >file02
~/hadoop/bin/hadoop dfs -mkdir input
~/hadoop/bin/hadoop dfs -put ~/file0* input
執行
~/hadoop/binhadoop wordcount.jar WordCount input output
=============
hadoop基本有兩部分dfs以及map-reducer
因為要分散式計算以及顧及到容錯,所以採取dfs
跟著map將輸入分散,然後再由reduce整合,map分散的時候輸入一組key1,value1,map運算完畢則是輸出另一組key2,value2,reduce則是根據key 2, value 2做資料整合,接著輸出key3, value3
從word count來說,key1可能是jab id或者hadoop產生的key,value則為一串文字,跟著將字串分解成單字,寫出的(key2, value2)可能是(hello,1),接著reducer收到後會把這些數值加總起來,跟著輸出(key3, value3)可能為(hello, 2)
2013年4月17日 星期三
system call open()
今天review linux character driver的時候,發現往往定義的file_operations的.open成員,參數擁有file以及inode參數,可是這個參數哪邊來的?
其實會對open()有好奇,主要也是之前一直在trace linux kernel source內一些socket的東西,socket本身由sockfs支援,不使用open()而用socket()來開啟inode,所以想說兩者的區別是?
kernel內用 inode 結構體用來表示data。因此,它和 file structure 用來表示一個打開了的fd並不相同。對於一個inde,可能會有多個 file structure 對應著多個已打開的多個fd,但是這都只能指向同一個 inode 結構。
回頭看open(),大多數的system call使用interrupt 0x80,所以很快地追蹤到sys_open()是理所當然的入口
簡化整個call stack為sys_open()=>filp_open()=>dentry_open()=>dentry_open()
在呼叫register_chrdev()的時候將有覆寫的file_operations賦予device
底下是一些重要的工作,完整的source code就不列了
sys_open() : 配置fd
filp_open() : 依賴路徑取得nameidata結構,跟著呼叫dentry_open()取回file instance
dentry_open() : 配置file instance,nameidata結構內包含了inode instance,此時將一些必要資料由inode拷貝到file instance,f->f_op = fops_get(inode->i_fop);,此時f->f_op->open(inode,f)就是當時register_chrdev()所註冊的file_operations。
參考資料:
http://hi.baidu.com/potyzhang/item/ae9993a919e86f17a8cfb793
http://hi.baidu.com/heiyebujianwo/item/fa7fe543d99b73ab61d7b9cb
其實會對open()有好奇,主要也是之前一直在trace linux kernel source內一些socket的東西,socket本身由sockfs支援,不使用open()而用socket()來開啟inode,所以想說兩者的區別是?
kernel內用 inode 結構體用來表示data。因此,它和 file structure 用來表示一個打開了的fd並不相同。對於一個inde,可能會有多個 file structure 對應著多個已打開的多個fd,但是這都只能指向同一個 inode 結構。
回頭看open(),大多數的system call使用interrupt 0x80,所以很快地追蹤到sys_open()是理所當然的入口
簡化整個call stack為sys_open()=>filp_open()=>dentry_open()=>dentry_open()
在呼叫register_chrdev()的時候將有覆寫的file_operations賦予device
底下是一些重要的工作,完整的source code就不列了
sys_open() : 配置fd
filp_open() : 依賴路徑取得nameidata結構,跟著呼叫dentry_open()取回file instance
dentry_open() : 配置file instance,nameidata結構內包含了inode instance,此時將一些必要資料由inode拷貝到file instance,f->f_op = fops_get(inode->i_fop);,此時f->f_op->open(inode,f)就是當時register_chrdev()所註冊的file_operations。
參考資料:
http://hi.baidu.com/potyzhang/item/ae9993a919e86f17a8cfb793
http://hi.baidu.com/heiyebujianwo/item/fa7fe543d99b73ab61d7b9cb
2013年3月30日 星期六
UP與Agile process的比較
以個人經驗提出兩者的差異

- agile使用user story捕捉需求,UP使用use case(文件,不是diagram)
- agile工程師往往一人身兼多職,從design architecture、designer、programmer
- UP並沒有強調是否一人身兼多職,但是往往將腳色獨立出來
- agile很強調Test,不是只有Unit Test還包含ATDD、BTDD
- agile認為文件必須要很精簡,UP則是比較鉅細靡遺
- agile很重視客戶合作,強調客戶需要配合軟體開發
- agile將"關係"維護在人之間,UP則是將關係落實到文件內
- Iterative方式
- 重視User Feedback
- 重視需求文件
- Risk driven
- 重視Architecture
- 重視business goal
agile實施起來未必比UP容易,agile裡的programmer往往一人身兼多種腳色,因此agile的programmer往往能力需要比較強,這也是為何早期XP強調pair programming的方式,一方面可以有feedback,另外一方面可以帶起新手
如果今天團隊內有人離職,UP因為將所有內容都記錄在文件上,理論上只要詳讀文件就可以理解,但是agile則是將一些隱含的關係放在人之間,一個programmer離職,恐怕新手只有user story以及code/test code可以讀取,有沒有design...等等的文件,則是看當時狀況
agile將某些資訊放到人之間,有個好處,由於資訊是共享的所以可以減少誤解,同時人在資訊上的更新,某種程度是比文件來的有彈性以及快速
agile最核心的難度恐怕在於改變人,因為過去客戶往往不瞭解他們的需求,同時也不了解軟體開發的一些資訊,客戶認為軟體專案如同販賣機一樣,只要錢投下去,軟體就會跑出來,agile正嘗試改變這一點
最後補上一個軟體工程的V-mode,由於agile很重視test,同時如果理解的話,應該就知道CMMI的 V&V在要求啥了。也就是只要了解軟體工程,自然可以滿足CMMI的Level 2, 3(除了4個跟organization相關的GG之外)
Specification by Example 書摘 (1)
這是一本不錯的書籍,雖然作者整理了一套需求捕捉的方法,但是如果沒有agile process的背景,可能會有點難以理解
Chapter 1.
一個好的需求文件,應該具備底下的優點
作者推崇一種稱為Living Documentation System的工具,也就是維護需求捕捉文件的系統概念,不管是word files或者web page...任何其他方式,這是一個要具備以上特色的系統
Chapter 2.
整本書的的需求捕捉架構大體上就被他的圖一言以蔽之,後面都是章節是一些實用技巧

Chapter 3.
作者注重Living Documentation System,他建議必須可以執行ATDD以及BTDD,因為一致性在文件系統很重要,作者使用Testing來維護系統的一致性,做這建議從一開始,需求就必須可以執行(executable)
書中也提到一個普遍性的誤會就是agile process不需要文件!其實這是根本上的錯誤。其實另外一個更廣泛的錯誤就是,開發人員認為環境一直改變,不需要維護需求,這才是更嚴重的問題,所以這樣的開發人員會把agile process當藉口
Chapter 1.
一個好的需求文件,應該具備底下的優點
- 眾人一致同意的功能
- 精確地描述
- 已完成此功能為目的
- 文件容易改變跟維護
- 避免太過詳細且浪費的需求描述
- 文件必須易懂
- 文件必須可以驗證
- 文件要具備一致性以及低成本的特性
- 文件必須符合process的iterations
作者推崇一種稱為Living Documentation System的工具,也就是維護需求捕捉文件的系統概念,不管是word files或者web page...任何其他方式,這是一個要具備以上特色的系統
Chapter 2.
整本書的的需求捕捉架構大體上就被他的圖一言以蔽之,後面都是章節是一些實用技巧

Chapter 3.
作者注重Living Documentation System,他建議必須可以執行ATDD以及BTDD,因為一致性在文件系統很重要,作者使用Testing來維護系統的一致性,做這建議從一開始,需求就必須可以執行(executable)
書中也提到一個普遍性的誤會就是agile process不需要文件!其實這是根本上的錯誤。其實另外一個更廣泛的錯誤就是,開發人員認為環境一直改變,不需要維護需求,這才是更嚴重的問題,所以這樣的開發人員會把agile process當藉口
2013年3月28日 星期四
新的語言特色!!??
java從java 5(or 6)?開始引入一連串的特色,讓我覺得這個語言愈來愈難掌握,愈來愈像是C++翻版:P
從annotation開始,annotation是類似comment,卻可以指使compiler去做一些處理,如果使用過hibernate的人就知道,可以連hibernate原本用來對應DB與java物件之間的xml檔案,全部寫入annotation上
跟著為了溶入generic programming,也就是在C++的template以及STL like的函數,引入了<?>這個符號,generic programming本人可是對他又愛又恨阿,他是非常的powerfull,但是又非常的難以maintain以及extend(對了,有時候還非常難以debug,visual c++ 6.0,光compiler吐出來的message,就根本不能看,更遑論runtime了),只敢使用STL或者Boost之類,其他人寫出的template lib,我可是十分警戒
後來因為其他需要,我開始使用python之類的語言,好處是十分快速的可以開發出一些prototype,來驗證自己的演算法,即使python的速度大概只能達到C++的1/10,不過如果我用C++開發大概要一個月,python我只要一個星期就搞定了XD 在驗證想法上,python有很大的優勢,只要把速度的問題交給機器去克服:P
在使用python之後,突然我想到了一個問題,為何PHP/Python這類不純粹是OO的語言,可以發展得如此之好,甚至於好過原本Java,不是一直在說OO可以幫忙處理、分析複雜的問題嗎??為何感覺PHP/Python愈發興盛?這意味著有某些是我們沒考慮到的!?這個問題似乎還沒有個終極的答案,我只有把它留在心裡
最近看了一下,java 8的新特色,OMG,開始支援一些PHP/Python的特色,比方說lambda的特色,讓java感覺又為了相容一些functional programming的特色以及generic的特色,"走回頭路",整個語法亂到了一個極致。在此同時,已也已經披露了OO的一些極限,比方說,在以前(java 6),你想弄個類似function pointer(C/C++),必須定義一個介面,走template method或者其他pattern的模式,光為了一個function pointer,必須多出一個interface再多出一個implementation,當然在OO上面有好處,但是在code上面可是多了不少阿
另外上面這些java的新特色,有個幾乎千篇一律的特色就是.....全部是在compiler的時候做手腳,也就是在.java轉換成.class的時候自動產生一些額外的code
回到核心的問題,是否一個語言在與時俱進的時候,必須要弄出一些"不倫不類"的特色,弄了一些code sugar,但是降低了原本的簡潔性?我倒是覺得java乾脆弄出個新的關鍵字,不要再把一些舊有的模式跟新的模式作一種奇怪的搭配,然後用compiler去處理這件事情。我只能說,我對這些新特色十分感冒orz
從annotation開始,annotation是類似comment,卻可以指使compiler去做一些處理,如果使用過hibernate的人就知道,可以連hibernate原本用來對應DB與java物件之間的xml檔案,全部寫入annotation上
跟著為了溶入generic programming,也就是在C++的template以及STL like的函數,引入了<?>這個符號,generic programming本人可是對他又愛又恨阿,他是非常的powerfull,但是又非常的難以maintain以及extend(對了,有時候還非常難以debug,visual c++ 6.0,光compiler吐出來的message,就根本不能看,更遑論runtime了),只敢使用STL或者Boost之類,其他人寫出的template lib,我可是十分警戒
後來因為其他需要,我開始使用python之類的語言,好處是十分快速的可以開發出一些prototype,來驗證自己的演算法,即使python的速度大概只能達到C++的1/10,不過如果我用C++開發大概要一個月,python我只要一個星期就搞定了XD 在驗證想法上,python有很大的優勢,只要把速度的問題交給機器去克服:P
在使用python之後,突然我想到了一個問題,為何PHP/Python這類不純粹是OO的語言,可以發展得如此之好,甚至於好過原本Java,不是一直在說OO可以幫忙處理、分析複雜的問題嗎??為何感覺PHP/Python愈發興盛?這意味著有某些是我們沒考慮到的!?這個問題似乎還沒有個終極的答案,我只有把它留在心裡
最近看了一下,java 8的新特色,OMG,開始支援一些PHP/Python的特色,比方說lambda的特色,讓java感覺又為了相容一些functional programming的特色以及generic的特色,"走回頭路",整個語法亂到了一個極致。在此同時,已也已經披露了OO的一些極限,比方說,在以前(java 6),你想弄個類似function pointer(C/C++),必須定義一個介面,走template method或者其他pattern的模式,光為了一個function pointer,必須多出一個interface再多出一個implementation,當然在OO上面有好處,但是在code上面可是多了不少阿
另外上面這些java的新特色,有個幾乎千篇一律的特色就是.....全部是在compiler的時候做手腳,也就是在.java轉換成.class的時候自動產生一些額外的code
回到核心的問題,是否一個語言在與時俱進的時候,必須要弄出一些"不倫不類"的特色,弄了一些code sugar,但是降低了原本的簡潔性?我倒是覺得java乾脆弄出個新的關鍵字,不要再把一些舊有的模式跟新的模式作一種奇怪的搭配,然後用compiler去處理這件事情。我只能說,我對這些新特色十分感冒orz
2013年3月21日 星期四
軟體設計與開發之野人獻曝(2)
我一直在想我有沒有資格寫一篇如何熟悉軟體開發過程的地圖,一直誠惶誠恐,覺得自已不夠資格,不過我換個角度來想,我把我自己的過程寫下來,或許對一些新踏入的人,可以有一些參考作用,就比較釋懷了
誠如會寫軟體未必需要懂得軟體工程,但是軟體工程可以幫助提綱挈領,統籌資料
個人認為的次序是 "軟體工程"=>"軟體流程",需求捕捉以及分析的工具,還需要"設計工具"(UML/Design pattern/Architecture Design),最後是"程式工具"(Refectoring),但是這裡缺乏了專案管理的工具,畢竟市面上太多,懂得流程後,尋找工具或者手動應該會輕鬆得多
軟體工程(統合概念的書籍)
 軟體開發流程的書籍 (UP, RUP, agile, scrum)
軟體開發流程的書籍 (UP, RUP, agile, scrum)





設計工具 (UML, design pattern, architecture design)




需求捕捉與管理


 程式(Code)工具
程式(Code)工具


其他(CMMI)

個人經驗,我是從RUP/UP入手,其實學習過程中,剛好另外一套稱為XP (eXtrem Programming)的學說興起,我個人在心理上比較認同XP(或許是自己是個programmer吧:-> )。使用RUP/UP的過程中,真的開始覺得他非常heavy,每件事情都快要鉅細靡遺,但是我也了解到了一個軟體開發過程中應該要有的大多數的成果(artifacts)
跟著也是一般人都會有的疑問,就是需求捕捉,之前寫得"從user case裡面直接分析出名詞跟動詞接著進入到設計階段"<=這絕對是簡化到誇張的講法,因為一般需要從需求裡面分析出domain model跟著才進化到desgin model
需求分析設計,一個講求what to do,一個講求how to do,但是在what to do之前呢?如何讓人們懂得溝通?一個是住在火星的programmer,一個是住在水星的客戶(business man),一個只認得code,一個只會寫的一嘴好程式(最常見的需求,我要做的跟XXX網站一樣,XXX請自行帶入yahoo, amazon, 淘寶...),在上面幾本書有很好的解析,writing effective use cases比較偏重UP/RUP的模式,Sepcification by Example, User Stories Applied則是Agile
至於設計工具GoF的design pattern就不用說了,真的是很多OOD的工具,另外一本Pattern Oriented Software Architecture(簡稱POSA)則是講究Architecture,如果懂得Architecture以及Pattern中間模糊的差異(其實有時候蠻難切開的,比方說broker有時是architecture有時又是pattern),另外一本Patterns of Enterprise Application Architecture則包含了許多web based的pattern跟架構
其他常用的code工具refatoring則是如何改善code工具,除了改善,我覺得後面另外一個很重要的精神是,不要隨便拋棄code(約爾趣談軟體有提到類似的精神),但是refactoring有個天生的缺點,很繁瑣,如果沒有自動化工具,我建議把一些類似rename等等太低接的動作捨棄,專注界面的改善比較好
最後是CMMI,CMMI這東西抽象化程度不輸給軟體工程,完全只有給出what to do(工程/流程面相),沒有how to do(實際執行),不妨將軟體流程的成果對應到CMMI上面去,因為軟體流程幾乎可以cover CMMI的Level 2跟Level 3,但是很不幸Level 3有四個SG (special goal)是屬於組織流程的,軟體工程無能為力,說實話Level 4跟Level 5我也很難領悟
誠如會寫軟體未必需要懂得軟體工程,但是軟體工程可以幫助提綱挈領,統籌資料
個人認為的次序是 "軟體工程"=>"軟體流程",需求捕捉以及分析的工具,還需要"設計工具"(UML/Design pattern/Architecture Design),最後是"程式工具"(Refectoring),但是這裡缺乏了專案管理的工具,畢竟市面上太多,懂得流程後,尋找工具或者手動應該會輕鬆得多
軟體工程(統合概念的書籍)
需求捕捉與管理
其他(CMMI)
個人經驗,我是從RUP/UP入手,其實學習過程中,剛好另外一套稱為XP (eXtrem Programming)的學說興起,我個人在心理上比較認同XP(或許是自己是個programmer吧:-> )。使用RUP/UP的過程中,真的開始覺得他非常heavy,每件事情都快要鉅細靡遺,但是我也了解到了一個軟體開發過程中應該要有的大多數的成果(artifacts)
跟著也是一般人都會有的疑問,就是需求捕捉,之前寫得"從user case裡面直接分析出名詞跟動詞接著進入到設計階段"<=這絕對是簡化到誇張的講法,因為一般需要從需求裡面分析出domain model跟著才進化到desgin model
需求分析設計,一個講求what to do,一個講求how to do,但是在what to do之前呢?如何讓人們懂得溝通?一個是住在火星的programmer,一個是住在水星的客戶(business man),一個只認得code,一個只會寫的一嘴好程式(最常見的需求,我要做的跟XXX網站一樣,XXX請自行帶入yahoo, amazon, 淘寶...),在上面幾本書有很好的解析,writing effective use cases比較偏重UP/RUP的模式,Sepcification by Example, User Stories Applied則是Agile
至於設計工具GoF的design pattern就不用說了,真的是很多OOD的工具,另外一本Pattern Oriented Software Architecture(簡稱POSA)則是講究Architecture,如果懂得Architecture以及Pattern中間模糊的差異(其實有時候蠻難切開的,比方說broker有時是architecture有時又是pattern),另外一本Patterns of Enterprise Application Architecture則包含了許多web based的pattern跟架構
其他常用的code工具refatoring則是如何改善code工具,除了改善,我覺得後面另外一個很重要的精神是,不要隨便拋棄code(約爾趣談軟體有提到類似的精神),但是refactoring有個天生的缺點,很繁瑣,如果沒有自動化工具,我建議把一些類似rename等等太低接的動作捨棄,專注界面的改善比較好
最後是CMMI,CMMI這東西抽象化程度不輸給軟體工程,完全只有給出what to do(工程/流程面相),沒有how to do(實際執行),不妨將軟體流程的成果對應到CMMI上面去,因為軟體流程幾乎可以cover CMMI的Level 2跟Level 3,但是很不幸Level 3有四個SG (special goal)是屬於組織流程的,軟體工程無能為力,說實話Level 4跟Level 5我也很難領悟
2013年3月16日 星期六
軟體設計與開發之野人獻曝(1)
發現很多人對於軟體工程嗤之以鼻,或者覺得這是一個象牙塔發展出來的東西,現實專案很少依照這樣的學理發展,我個人倒是認為,軟體工程是提供一個對照,軟體也好、硬體也罷,一定有個生產流程,但是過程中應該產生出來的東西是否被"省略"了
比方說,規格書被省略是最常看到的,軟體好像就從空氣中跑出來了,事實上不是這樣,需求或許未被寫出來,可是他一定留在某些人的腦袋當中
另外一個就是,軟體工程有時太過高度抽象畫,很難落實,或許流程(process)會比較貼近實際,但是流程往往又需要很高的門檻,比方說要熟悉UML(UML只是描述語言,並不是完全依賴於某種流程,反過來倒是很多流程依賴UML)
流程(process)會開始解釋,如何從需求捕捉到系統分析,也就是從what to do到how to do,從抽象的描述到軟體設計開始,如果沒有實際經歷,往往也是落到跟軟體工程一樣的結論,這是一個高階的開發流程,並沒有辦法使用
流程(process)為何比軟體工程更貼近實際呢?因為流程往往綁定特定模式,比方OO,但是軟體工程則是更抽象,喜歡用lisp這種非OO開發也可以,要用OO流程開發也可以,換句話說,軟體工程工過程中省略了某些部分,使得讀者很難連貫跟理解
以RUP為例子,流程(process)會解釋如何從use case的描述之中抽出名詞跟動詞,如何組合名詞跟動詞成為class,在設計的時候會進一步將class抽象成其他class,常見的手法就是套用design pattern。但是如果是The object primer書的agile模式,則是從user story轉換為use case diagram然後慢慢地轉換為class,步驟、方法上跟精神上是有所不同的
因為時間的關係,先簡單寫到這裡,可以看到,要懂得一種process至少知道軟體開發過程,要懂得UML,要懂得design pattern,還要知道某些開發者的角色扮該執行怎樣的工作,所以不是一個簡單的過程,流程(process)也是一種方法論,懂得之後未必需要完全依照執行,但是可以加深取捨的決策。又如我最一開始說的,即使沒有任何需求、設計文獻就落實到了code,但是這些東西是保留在程式設計師或者客戶腦袋中,不落實將會一些效應的存在(比方引進新人員,要花很多工夫在訓練新人融入專案)
軟體工程、軟體開發流程是否需要懂??我說: Everything is about the trade-off.
比方說,規格書被省略是最常看到的,軟體好像就從空氣中跑出來了,事實上不是這樣,需求或許未被寫出來,可是他一定留在某些人的腦袋當中
另外一個就是,軟體工程有時太過高度抽象畫,很難落實,或許流程(process)會比較貼近實際,但是流程往往又需要很高的門檻,比方說要熟悉UML(UML只是描述語言,並不是完全依賴於某種流程,反過來倒是很多流程依賴UML)
流程(process)會開始解釋,如何從需求捕捉到系統分析,也就是從what to do到how to do,從抽象的描述到軟體設計開始,如果沒有實際經歷,往往也是落到跟軟體工程一樣的結論,這是一個高階的開發流程,並沒有辦法使用
流程(process)為何比軟體工程更貼近實際呢?因為流程往往綁定特定模式,比方OO,但是軟體工程則是更抽象,喜歡用lisp這種非OO開發也可以,要用OO流程開發也可以,換句話說,軟體工程工過程中省略了某些部分,使得讀者很難連貫跟理解
以RUP為例子,流程(process)會解釋如何從use case的描述之中抽出名詞跟動詞,如何組合名詞跟動詞成為class,在設計的時候會進一步將class抽象成其他class,常見的手法就是套用design pattern。但是如果是The object primer書的agile模式,則是從user story轉換為use case diagram然後慢慢地轉換為class,步驟、方法上跟精神上是有所不同的
因為時間的關係,先簡單寫到這裡,可以看到,要懂得一種process至少知道軟體開發過程,要懂得UML,要懂得design pattern,還要知道某些開發者的角色扮該執行怎樣的工作,所以不是一個簡單的過程,流程(process)也是一種方法論,懂得之後未必需要完全依照執行,但是可以加深取捨的決策。又如我最一開始說的,即使沒有任何需求、設計文獻就落實到了code,但是這些東西是保留在程式設計師或者客戶腦袋中,不落實將會一些效應的存在(比方引進新人員,要花很多工夫在訓練新人融入專案)
軟體工程、軟體開發流程是否需要懂??我說: Everything is about the trade-off.
2013年2月20日 星期三
unix network programming: chapter 15 nonblocking IO
這一章特別有趣,因為之前node.js對於nonblocking IO有點消化不良,慢慢地體會到,nonblocking IO的思維之後,覺得這樣的設計對於performance真很有幫助,不過控制也是比較困難,這篇文章不會提到書中如何實作,想了解的網友可以直接翻閱書籍
最讓人直接聯想到的nonblocking IO思維是connect()這個function,如果說只有一個連線,個人認為block反而容易理解,nonblocking沒太大用途。但是想像一個應用,比方設計一個由地理位置分析周遭環境的application,你需要透過超過五十頁的網頁內容來整合,這時候connect()會block就變成了一個效能的瓶頸,因為每個網頁都要等前一個網頁的3-way handshake完成才能繼續工作,如果改用nonblocking,幾乎可以在短時間內就發出五十個http請求,這樣就快得多了
但是nonblocking其實也有些副作用
回過頭來說,其實上面選用除了第一個之外,各有各的不同考量,我給出的建議如下
nonblocking IO: performance
fork(): different task or paralle task
thread: similar task or share data
如果要同時發出大量的連線需求,使用nonblocking是比較好的選擇,如果資源充裕(memory很多/cpu也很強)使用fork()也比較好,因為thread遇到block IO整個process就被block住,其他thread也失去了活動機會,根本沒有幫助
如果說需要share data,基本上挑選thread會比較好,因為thread在share data表現上比IPC容易一點,雖然也有同步資料的問題,但是同步資料在fork()也是無法迴避的。相同的動作,如http server讀取檔案,使用thread就是不錯的選擇
fork()比thread的缺點就是要配置大量的記憶體空間,還有share data要透過IPC,好處是不會被block住。
此外process在kernel上分配CPU time的機會也比thread好,比方說目前server有一個process,programmer寫一個抓取遠端資料分析的程式,為了增進效能,將其一分為二,一個使用fork(),一個使用thread,那麼一個是三個process,一個是兩個process,如果均勻分配,使用fork()方式的將會佔據67%左右的CPU,另外一個使用thread只有33%。當然這是一種武斷的算法,要看使用的CPU/IO乃至於網路的情況而定
所以到底是該用nonblocking IO或者blocking IO?該用thread or fork()?其實都有不同的考量,由於richard stevens已經去世了,新版(3ed)的不知道有沒有討論到asynchronous IO??這或許再看看,在2ed richard stevens只是輕輕帶過這種IO的存在,事實上,網路上已經有開始有使用asynchrounous IO的文章了,應該是值得期待的
最讓人直接聯想到的nonblocking IO思維是connect()這個function,如果說只有一個連線,個人認為block反而容易理解,nonblocking沒太大用途。但是想像一個應用,比方設計一個由地理位置分析周遭環境的application,你需要透過超過五十頁的網頁內容來整合,這時候connect()會block就變成了一個效能的瓶頸,因為每個網頁都要等前一個網頁的3-way handshake完成才能繼續工作,如果改用nonblocking,幾乎可以在短時間內就發出五十個http請求,這樣就快得多了
但是nonblocking其實也有些副作用
- nonblocking非常耗用CPU效能
- nonblocking的程式碼相對難以掌握,可以參考書中,由blocking/select IO(40 lines)膨脹成nonblocking IO的135 lines,可見一斑,
- 書中沒有提到的流程控制相對困難,可參考node.js的flow control部分,就知道連流程控制也是一大挑戰
- block and wait version : 354(s)
- select and blocking : 12.3 (s)
- nonblocking IO: 6.9 (s)
- fork(): 8.7 (s)
- thread : 8.5 (s)
回過頭來說,其實上面選用除了第一個之外,各有各的不同考量,我給出的建議如下
nonblocking IO: performance
fork(): different task or paralle task
thread: similar task or share data
如果要同時發出大量的連線需求,使用nonblocking是比較好的選擇,如果資源充裕(memory很多/cpu也很強)使用fork()也比較好,因為thread遇到block IO整個process就被block住,其他thread也失去了活動機會,根本沒有幫助
如果說需要share data,基本上挑選thread會比較好,因為thread在share data表現上比IPC容易一點,雖然也有同步資料的問題,但是同步資料在fork()也是無法迴避的。相同的動作,如http server讀取檔案,使用thread就是不錯的選擇
fork()比thread的缺點就是要配置大量的記憶體空間,還有share data要透過IPC,好處是不會被block住。
此外process在kernel上分配CPU time的機會也比thread好,比方說目前server有一個process,programmer寫一個抓取遠端資料分析的程式,為了增進效能,將其一分為二,一個使用fork(),一個使用thread,那麼一個是三個process,一個是兩個process,如果均勻分配,使用fork()方式的將會佔據67%左右的CPU,另外一個使用thread只有33%。當然這是一種武斷的算法,要看使用的CPU/IO乃至於網路的情況而定
所以到底是該用nonblocking IO或者blocking IO?該用thread or fork()?其實都有不同的考量,由於richard stevens已經去世了,新版(3ed)的不知道有沒有討論到asynchronous IO??這或許再看看,在2ed richard stevens只是輕輕帶過這種IO的存在,事實上,網路上已經有開始有使用asynchrounous IO的文章了,應該是值得期待的
2013年2月18日 星期一
unix network programming書摘 -- Part 1
只有記錄我認為容易忽略的地方,文章內不會有TCP/IP的詳細過程,可以參考richard stevens的另外一本大作TCP/IP Illustrate,另外手邊有的unix network programming一書是2ed
Chapter 1
伺服器端
主要流程填寫sockaddr_in結構,socket()=>bind()=>listen()=>accept()=>read()/write()=>close()
客戶端
Chapter 2
重要的為TCP以及UDP的特色,以及richard stevens書中那張state diagram,中間牽涉到如何透3-way handshake建立連線,以及何時會斷線,為何TIME_WAIT狀態要等2MSL

Chapter 3
Chapter 4
重點之一,流程圖,書中逐一解說各個function用途

chapter 5
chapter 6
介紹常見的socket options,分成幾個層次,一般socket options、IPv4 options、IPv6 options、ICMP options、TCP options。一般socket options指的是大多與protocol獨立無關,由kernel透過與protocol無關的code設定。
我摘要了幾個前面常常碰見的options,有些options大多集中在書本前面,且偏向一般socket options
Chapter 8
UDP介紹,如同TCP一樣,有張流程圖,不過不是一定的

Chapter 1
伺服器端
1: #include "unp.h"
2: #include <time.h>
3:
4: int
5: main(int argc, char **argv)
6: {
7: int listenfd, connfd;
8: struct sockaddr_in servaddr;
9: char buff[MAXLINE];
10: time_t ticks;
11:
12: listenfd = Socket(AF_INET, SOCK_STREAM, 0);
13:
14: bzero(&servaddr, sizeof(servaddr));
15: servaddr.sin_family = AF_INET;
16: servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
17: servaddr.sin_port = htons(13); /* daytime server */
18:
19: Bind(listenfd, (SA *) &servaddr, sizeof(servaddr));
20:
21: Listen(listenfd, LISTENQ);
22:
23: for ( ; ; ) {
24: connfd = Accept(listenfd, (SA *) NULL, NULL);
25:
26: ticks = time(NULL);
27: snprintf(buff, sizeof(buff), "%.24s\r\n", ctime(&ticks));
28: Write(connfd, buff, strlen(buff));
29:
30: Close(connfd);
31: }
32: }
主要流程填寫sockaddr_in結構,socket()=>bind()=>listen()=>accept()=>read()/write()=>close()
客戶端
1: #include "unp.h"
2:
3: int
4: main(int argc, char **argv)
5: {
6: int sockfd, n;
7: char recvline[MAXLINE + 1];
8: struct sockaddr_in servaddr;
9:
10: if (argc != 2)
11: err_quit("usage: a.out <IPaddress>");
12:
13: if ( (sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
14: err_sys("socket error");
15:
16: bzero(&servaddr, sizeof(servaddr));
17: servaddr.sin_family = AF_INET;
18: servaddr.sin_port = htons(13); /* daytime server */
19: if (inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0)
20: err_quit("inet_pton error for %s", argv[1]);
21:
22: if (connect(sockfd, (SA *) &servaddr, sizeof(servaddr)) < 0)
23: err_sys("connect error");
24:
25: while ( (n = read(sockfd, recvline, MAXLINE)) > 0) {
26: recvline[n] = 0; /* null terminate */
27: if (fputs(recvline, stdout) == EOF)
28: err_sys("fputs error");
29: }
30: if (n < 0)
31: err_sys("read error");
32:
33: exit(0);
34: }
流程為填寫sockaddr_in結構,socket()=>connect()=>read()/write()=>close()Chapter 2
重要的為TCP以及UDP的特色,以及richard stevens書中那張state diagram,中間牽涉到如何透3-way handshake建立連線,以及何時會斷線,為何TIME_WAIT狀態要等2MSL

- 個人認為重要的觀念是TCP/UDP為全雙工,也就是系統如何處理這樣的概念,從這裏面衍生出了不少問題
- TCP使用socket pair的概念來辨識連線,也就是Server IP+Server Port+Client IP+Client Port,因為UDP沒有連線概念的約束(也可以自行實作,但是TCP天生幫programmer處理這些)
- 同時開始考慮,一台機器可能不只一個網路介面,或者說不只一張網路卡,一個service(如FTP)可以同時在所有卡啟動,只要指定socket結構內為INADDR_ANY即可,如果要綁定數張,就只能一個一個來
- 另外書中提到kernel緩衝區的可以用SO_SNDBUF/SO_RCVBUF(setsockopt())來調整,TCP因為有window size的關係,照理不應該有buffer用盡的問題,但是UDP卻會,又加上UDP是unreliable,buffer一旦滿了就只會drop,連通知都不會有
Chapter 3
- 因為unix/linux設計socket不只可以用在ethernet還可以用在domain socket上面(一種IPC),所以網路上用的是sockaddr_in結構但是在connect()/bind()/accpet()...參數用的卻是sockaddr結構(一種所謂generic socket結構),所以在呼叫這些api往往形態要轉型
- bind()、connect()、sendto()是將資料由user space傳送到kernel space
- accept()、recvfrom、getsockname()、getpeername()則是由kernel space回傳資料到user space
- byte order的問題,網路上使用的是big-edian,但是intel cpu是little-edian,所以有這問題,通常有四個函數來處理htons()、htonl()、ntohs()、ntohl(),h表示host、n表示network、s表示16bits、l表示32bits
- 新的由IP字串取得address的function為intet_pton()以及反向函數inet_ntop()其中p表示presentation
- 作者時做了好一些輔助函數,很有參考價值
Chapter 4
重點之一,流程圖,書中逐一解說各個function用途

- socketaddr_in要轉型的原因如前一章,另外要注意,因為可以合乎各種family,所以在connect()/bind()/accept()除了轉型之外,還需要傳入結構大小的指標
- 這裡衍生出一個重要的觀念,TCP server一定要bind()嗎?答案是不一定,可以由系統指派,之後在用getsockname()取回sockaddr得知,而client的sockaddr資訊則可以用getsockpeername()取回
- fork()解決一小部分 socket為了全雙工所面臨的問題,因為程式不能因為系統呼叫而block住
chapter 5
- 書中提到了系統的問題,也就是signal會干擾正常流程,以及如何避免child process變成zombie的問題,使用waitpid()來解決,wait()因為kernel不queue signal可能還是會產生zombie
- SIGPIPE有可能是因為網路上遇到RST訊號,這屬於網路問題,但是unix反應到process上變成signal,必須妥善處理才能避免連線的問題
chapter 6
- 解說了blocking/nonblocking IO跟IO multiplexing、還有signal IO、asynchronous IO
- select()函數示範了IO multiplexing,這個函數可以簡單的處理網路的IO以及一般的輸入,但是中間呼叫其他system call還是有可能會block整個process,所以要小心
- select() -- read ready
- 正常狀況,資料高於低水位,可以透過setsockopt()的SO_RCVLOWAT調整低水位
- 對方已經關閉連線,會回傳EOF
- 在完成connected的queue中有可用的socket
- 有sock error存在,read()回傳-1,利用getsockopt()取得SO_ERROR資料
- select() -- write ready
- TCP在socket已經連線的時候可以寫入,或者UDP/TCP寫入資料多於低水位的時候,使用setsockopt()的SO_SNDLOWAT調整
- 連線端已經關閉寫入,會產生SIGPIPE
- 網路有sock error存在,write()回傳是-1,利用getsockopt()取得SO_ERROR資料
- shutdown()函數以及setsockopt()的SO_LINGER可以調整關閉socket時候的動作,必須考慮到網路的封包。
- close()只是關閉write/read fd並沒有關閉網路連線(或者TCP沒有送出FIN)
介紹常見的socket options,分成幾個層次,一般socket options、IPv4 options、IPv6 options、ICMP options、TCP options。一般socket options指的是大多與protocol獨立無關,由kernel透過與protocol無關的code設定。
我摘要了幾個前面常常碰見的options,有些options大多集中在書本前面,且偏向一般socket options
- SO_BROADCAST : 廣播
- SO_ERROR : 網路出錯
- SO_KEEPALIVE : 兩個小時透過封包確定TCP連線還存活著
- SO_LINGER : FIN訊號的處理
- SO_RCVBUF/SO_SNDBUF : 設定TCP/UDP的buffer,TCP不用特意調整,他有window size機制
- SO_RCVLOWAT/SO_SNDLOWAT : 資料的低水位控制,有關效率以及select()
- SO_REUSEPORT :
- SO_RESUEADDR : 只要IP不同,特別不用等待2MSL就可以重新bind()
- TCP_KEEPALIVE : 要開啟這個選項就要同時開啟SO_KEEPALIVE
- TCP_NODELAY : nagle演算法實作
Chapter 8
UDP介紹,如同TCP一樣,有張流程圖,不過不是一定的

- 不是一定的理由是,用戶端可以呼叫bind()跟connect(),當然兩者也可以都忽略
- 書中探討到了UDP失去了TCP特色的問題,比方UDP無法得知連線IP/Name,UDP沒有流量控制,UDP沒有重傳機制
- UDP因為不做3-way handshake,所以無法確定client/server是透過哪個IP或者介面卡傳輸,兩邊都可以從自己主機上的任一IP或者介面卡回應另一方
- UDP可以透過IP比對,或者DNS比對(多個IP對應到單一domain name),來驗證資料來源
- UDP可以透過前一點機制與Timeout設定來確定封包有沒有送達
- UDP可以透過SO_RCVBUF改善流量問題
- UDP的好處之一,可以透過一個client同時對多個server提出要求,但是會引發一個問題是ICMP的訊息將是非同步產生
- 其他可以參考我之前寫的socket FAQ
2013年2月17日 星期日
socket API FAQ
我整理一些比較常見的疑問點
Q. TCP server是否一定要呼叫bind()?
A. 不一定,如果不呼叫bind(),系統會自動配置,後面再由getsockname()取得資訊
Q. bind()是甚麼意思?
A. 表示將protocol, IP, port number綁訂在一起,某種程度也是指定介面卡(思考有多張網路卡以及每張網路卡只有單一IP)
Q. UDP的客戶端不需要呼叫,也不可以呼叫bind()?
A. 不是,如前面所說,UDP也可以透過bind()指定介面卡(IP)
Q. close()會關閉連線?
A. 不會,close()會馬上返回程式,他只有關閉了read/write的fd,並且將該fd的reference count減一,只有當reference count為0的時候才會開始關閉連線(FIN),但也不是馬上關閉,kernel還是會嘗試將還存在queue的封包送出或者接收依舊在網路的封包,過程可以由setsockopt()的SO_LINGER控制,如果要馬上關閉必且忽略reference count限制可以呼叫shutdown()
Q. connect()只有TCP用得到,UDP必須使用recvfrom()以及sendto()?
A. connect()在UDP內依舊可以使用,只是語意不如TCP會完成3-way handshake,UDP呼叫connect是將sockaddr註冊給kernel,並取得一socket fd
Q. connect()在UDP使用的方式?
A. 如前面一問題,註冊後可取得socket fd,之後就可以用read()/write()函數來操作,同時,因為recvfrom()跟sendto()每次都要將sockaddr向kernel註冊,使用connect()則不用,在大量訊息傳送的時候使用connect()/read()/write()效能會優於使用recvfrom()跟sendto()
Q. TCP server是否一定要呼叫bind()?
A. 不一定,如果不呼叫bind(),系統會自動配置,後面再由getsockname()取得資訊
Q. bind()是甚麼意思?
A. 表示將protocol, IP, port number綁訂在一起,某種程度也是指定介面卡(思考有多張網路卡以及每張網路卡只有單一IP)
Q. UDP的客戶端不需要呼叫,也不可以呼叫bind()?
A. 不是,如前面所說,UDP也可以透過bind()指定介面卡(IP)
Q. close()會關閉連線?
A. 不會,close()會馬上返回程式,他只有關閉了read/write的fd,並且將該fd的reference count減一,只有當reference count為0的時候才會開始關閉連線(FIN),但也不是馬上關閉,kernel還是會嘗試將還存在queue的封包送出或者接收依舊在網路的封包,過程可以由setsockopt()的SO_LINGER控制,如果要馬上關閉必且忽略reference count限制可以呼叫shutdown()
Q. connect()只有TCP用得到,UDP必須使用recvfrom()以及sendto()?
A. connect()在UDP內依舊可以使用,只是語意不如TCP會完成3-way handshake,UDP呼叫connect是將sockaddr註冊給kernel,並取得一socket fd
Q. connect()在UDP使用的方式?
A. 如前面一問題,註冊後可取得socket fd,之後就可以用read()/write()函數來操作,同時,因為recvfrom()跟sendto()每次都要將sockaddr向kernel註冊,使用connect()則不用,在大量訊息傳送的時候使用connect()/read()/write()效能會優於使用recvfrom()跟sendto()
2013年2月16日 星期六
The art of readable code摘要 -- 特定題材
testing and readability (測試以及可靠性)
make tests easy to read and maintain (讓測試容易理解及維護)
測試可以讓人勇敢的修改程式碼,所以可以提升維護性
what’s wrong with this test? (測試發生了甚麼事?)
舉例下面的測試,並且慢慢修正
void Test1() {
vector<ScoredDocument> docs;
docs.resize(5);
docs[0].url = "http://example.com";
docs[0].score = -5.0;
docs[1].url = "http://example.com";
docs[1].score = 1;
...
SortAndFilterDocs(&docs);
assert(docs.size() == 3);
assert(docs[0].score == 4);
assert(docs[1].score == 3.0);
assert(docs[2].score == 1);
}
making this test more readable (讓測試更具備可讀性)
文章建議將docs[0].property=xxx,包裹成function,命名為類似addDoc()比較有可讀性,更進一步或許可以建立起string to docs的function,方便產生資料
making error messages readable (使錯誤訊息更具備可讀性)
建議assert錯誤的時候可以輸出更有用的訊息
choosing good test inputs (選擇一個恰當的輸入)
建議簡化以及多種的輸入,做到良好的測試
naming test functions (為測試函數命名)
Test1沒有意義,測試命名要有意義
what was wrong with that test? (測試發生了甚麼事?)
回顧前面的問題
test-friendly development (友善的測試開發)
作者同意TDD (Test Driven Development)的基本想法,並且列出了許多有問題的特徵
going too far (想太多)
作者列出三點可能想太多的盲點
- Sacrificing the readability of your real code, for the sake of enabling tests.
- Being obsessive about 100% test coverage.
- Letting testing get in the way of product development.
designing and implementing a “minute/hour counter” (實作 分鐘/小時 計數器)
the problem
defining the class interface
作者做一總結回顧,舉例以及技巧應用
================我的心得================
可以比較依些類似unit test的構想,以及M$談論測試的書籍,會發現測試真的是一個專門的事情,好比光100% coverage,在M$上是"必須"達到的事情,此外agile process有些建議則是不應該花太多精神在"照顧"test,test應該保持直觀、快速開發,比方說將docs[0].property=xxx包裝成為函數,可能就不大受歡迎,因為可能引入更多的bug,又要花更多時間去維護test,頗有得不償失的味道
The art of readable code摘要 -- 重整程式碼
extracting unrelated subproblems (分解問題)
aggressive是一個重要精神,讓functions可以組裝
introductory example: findClosestLocation() (範例)
將某些codes blocks依照他們工作的屬性獨立出來,並且賦予一個高階的function name,可以增加可讀性(refactoring: extra method)
pure utility code (純粹工具程式)
將一些常用的程式整合成一常見的function
other general-purpose code
同上,作者舉例javascript上一個format ajax response的function
create a lot of general-purpose code
project-specific functionality
開發工具functions
simplifying an existing interface (簡化已經存在的介面)
符合agile的open/close精神,減少不必要的接觸,就可以減少犯錯
reshaping an interface to your needs (從新修整介面成為你需要的模式)
refactoring(?)
taking things too far (不要考慮太多)
不要過分分割
one task at a time (一次只處理一件事情)
tasks can be small (分割工作)
將工作分割以及簡化成為一個小步驟
extracting values from an object (從分解數值看問題)
這部份建議看原著,有點類似refactoring
作者舉例javascript一個類似住址的結構變數假設就是addr,裡面有town, city, state, country,然而有一處理函數需要回傳[town|city|state], country,前三者選擇一個,優先權是town>city>state,直覺的寫法就是一串提取addr[town]...然後if ...,作者認為這樣子不大好,最好一次將次個結構提取出來,跟著做一串判斷
另一解法方式是類似如此
if (country === "USA") {
first_half = town || city || "Middle-of-Nowhere";
second_half = state || "USA";
} else {
first_half = town || city || state || "Middle-of-Nowhere";
second_half = country || "Planet Earth";
}
return first_half + ", " + second_half;
但作者提到這是熟悉javascript的方式
a larger example
turning thoughts into code (精煉你的想法)
describing logic clearly (清楚描述你的logic)
作者舉例之前Simplifying Loops and Logic的應用,顯示if~else需要簡化
knowing your libraries helps (讓你的函式庫有用)
書中描述一jquery範例實作網頁上tooltip顯示,一開始程式碼使用index跟slice()作為解析,更改的程式碼意圖表示用更抽象(藉由jquery)與一致的方式顯示tooltip。加上註解,這樣可以提高程式碼resue的機率
applying this method to larger problems (分割與處理)
作者提供了一個python處理transaction的方式,但是如果以直觀的方式寫code會出現很凌亂,書中把相似的片段加以集合以及問題加以分割
writing less code (精簡程式碼)
don’t bother implementing that feature—you won’t need it (不要實作你不需要的特色)
不要過分design
question and break down your requirements (處理你的需求)
不斷更新、改進需求
keeping your codebase small (保持程式碼的精簡)
愈少的程式碼愈好處理,必要時移除不必要的程式碼
be familiar with the libraries around you (工欲善其事,必先利其器)
花十五分鐘好好讀讀你用到的library
example: using unix tools instead of coding
===============我的感想===============
這裡提到的技巧都很像refactoring以及約耳趣談軟體內提到的,重複改善軟體(約耳並不鼓勵丟棄code),透過種種的精鍊,可以完成更好的code,除非本來的code真的一無可取
code改進好比改寫論文,必須要更加精簡,過程中就不斷地提升設計以用法,讓他們更精簡、更泛用,然則refactoring比較介於design與code之間,這本書則比較介於語法語code之間
此外很多程式設計師的意見並不一致,比方說這裡鼓勵使用人家的library,但是約耳點出,有時library也是要付出代價的,尤其是library往往也有他的bug,還有自己是否能控制library(指能夠理解並且改寫)。事實上library引用有時的確是很麻煩,好比tomcat最常遇到就是升級的時候一堆library需要升級的麻煩,之前專案的一堆程式碼是否需要改寫?此時問題已提升到configure management的範疇
The art of readable code摘要 -- 簡化迴圈與邏輯
making control flow easy to read (使得流程容易理解)
the order of arguments in conditionals
the order of if/else blocks
the ?: conditional expression (a.k.a. “ternary operator”)
建議不要使用,易懂比省空間重要得多
avoid do/while loops (避免使用避免使用do/while)
把condition放在前面比較好
returning early from a function (儘早回傳value)
the infamous goto (惡名昭彰的goto)
在linux kernel內有不少goto,但是他們使用goto通常是跳到"結尾",並不是當作插入流程控制
minimize nesting (減少loop nesting)
可以簡潔流程
是否你新增的程式碼夠清楚明白嗎?不要因為增加簡單處理而增加很多的理解程式是複雜度
can you follow the flow of execution? (你能夠理解流程嗎?)
一些高階的手法,有其必要的代價,如果可以的話,使用簡單的模式,避免使用他們
- Programming construct=>How high-level program flow gets obscured
- threading=>It’s unclear what code is executed when.
- signal/interrupt=>handlers Certain code might be executed at any time.
- exceptions=>Execution can bubble up through multiple function calls.
- function pointers & anonymous functions=>It’s hard to know exactly what code is going to run because that isn’t known at compile time.
- virtual methods=>object.virtualMethod() might invoke code of an unknown subclass.
breaking down giant expressions (分解太長的表示表示式)
explaining variables (示意變數)
if line.split(':')[0].strip() == "root": ...改為username = line.split(':')[0].strip()
讓一個變數來表達他的用意
summary variables (結論變數)
final boolean user_owns_document = (request.user.id == document.owner_id);
如果條件要反覆使用到,使用一個變數取代他
using de morgan’s laws (使用de morgan定理)
使用de morgan's laws化簡條件判斷式
abusing short-circuit logic (避免濫用"短路"邏輯)
避免誤用短路邏輯,因為短路邏輯會造成其他邏輯部分沒有執行,尤其如果邏輯判斷內的每個method/function都期望他們被執行到
example: wrestling with complicated logic
嘗試為複雜的邏輯找到優雅的表示法
breaking down giant statements (拆解太長的表示式)
試著使用explaining variables跟summary variables來取代跟化簡太長的表示式
another creative way to simplify expressions (另一種簡化表示式的創意方式)
適當的使用MACRO來以更簡潔的方式簡化expression
variables and readability (變數以及可能性)
eliminating variables (減少變數)
如果使用了explaining variables以及summary variables,要注意是否這個變數有存在的必要,如果他們沒有長期存在的意義,或許直接使用expression會比較好
shrink the scope of your variables (縮小變數的範圍)
儘量減少variable的生命週期以及範圍,如果沒有存在的必要,就不要讓它存在
prefer write-once variables (使用常數)
多使用constant,因為愈少操作,出錯機率愈少
a final example
=============我的心得=============
這部分有很多語言相依的實例,但是有些已經開始牽涉到執行以及正確性了,不是單單可讀性的問題
比方說summary/explaining variables的使用,曾經有人建議不要使用,理由是,每一次使用summary/explaining variables等同增加犯錯的風險,他們堅持使用function call好過用variable傳遞。其實我覺得使用這些變數的確有這樣的風險,但是同時又可以增加效能以及可讀性,作者自己也在eliminating variables提出幾個類似反例例子
所以上面的技巧使用很端看場合決定,沒有一個絕對好的答案,都是有一些trade-off存在
至於有些部分我沒有節錄是因為感覺書上"技巧"實在有點太過over了
IP Header其實很多平台不一樣
IP header format defined in RFC 791:
IP header data sturcture in Linux:
IP header data structure in ns2:
IP header data structure in GloMoSim:
IP header data structure in OPNET:
Linux data structure defines fields in bits while simulators define them in common C data types other than bits. Since Linux, which directly runs on hardware, benefits from bit operation. But simulators cannot. So there's no need to bother fields in bits.
Comparing the structures in ns2 and OPNET, we find OPNET struture much more complex, since it supports many technologies in its IP module, including IP tunneling, MPLS, VPN, etc.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
IP header data sturcture in Linux:
/* /usr/include/netinet/ip.h */
struct iphdr
{
#if __BYTE_ORDER == __LITTLE_ENDIAN
unsigned int ihl:4;
unsigned int version:4;
#elif __BYTE_ORDER == __BIG_ENDIAN
unsigned int version:4;
unsigned int ihl:4;
#else
# error "Please fix <bits/endian.h>"
#endif
u_int8_t tos;
u_int16_t tot_len;
u_int16_t id;
u_int16_t frag_off;
u_int8_t ttl;
u_int8_t protocol;
u_int16_t check;
u_int32_t saddr;
u_int32_t daddr;
/*The options start here. */
};
IP header data structure in ns2:
/* src/ns-<ver>/common/ip.h */
struct hdr_ip {
/* common to IPv{4,6} */
ns_addr_t src_;
ns_addr_t dst_;
int ttl_;
/* Monarch extn */
// u_int16_t sport_;
// u_int16_t dport_;
/* IPv6 */
int fid_; /* flow id */
int prio_;
static int offset_;
inline static int& offset() { return offset_; }
inline static hdr_ip* access(const Packet* p) {
return (hdr_ip*) p->access(offset_);
}
IP header data structure in GloMoSim:
typedef struct ip {
unsigned int ip_v:3, /* version */
ip_hl:5, /* header length */
ip_tos:8, /* type of service */
ip_len:16; /* total length */
unsigned int ip_id:16,
ip_reserved:1,
ip_dont_fragment:1,
ip_more_fragments:1,
ip_fragment_offset:13;
unsigned char ip_ttl; /* time to live */
unsigned char ip_p; /* protocol */
unsigned short ip_sum; /* checksum */
long ip_src,ip_dst; /* source and dest address */
} IpHeaderType;
IP header data structure in OPNET:
/* Data structure for fields in the */
/* ip datagram. */
typedef struct
{
OpT_Packet_Size orig_len;
int ident;
OpT_Packet_Size frag_len; /* payload_length for IPv6 */
/* For IPv6 pkts this does not include the length */
/* of the fragmentation header. */
int ttl; /* hop_limit for IPv6 */
InetT_Address src_addr;
InetT_Address dest_addr;
int protocol; /* next_hdr for IPv6 */
int tos; /* traffic_class for IPv6 */
int offset; /* The offset of this fragment */
/* The following two fields are for ECN - RFC#3168. */
/* The ECT field is set in the datagram only if the */
/* transport protocol is capable of handling the */
/* explicit congestion notification. The CE bit */
/* actually contains information about congestion. */
int CE;
int ECT;
/* The remaining fields are for */
/* simulation efficiency, and are */
/* not actual fields in a packet. */
int frag;
int connection_class;
int src_internal_addr;
int dest_internal_addr;
IpT_Compression_Method compression_method;
OpT_Packet_Size original_size;
OpT_uInt8 options_field_set; /* Boolean field, uint8 is being used to conserve memory. */
OpT_uInt8 tunnel_pkt_at_src; /* Boolean set to true in outer pkt at src of tunnel */
double decompression_delay;
InetT_Address next_addr;
/* The tunnel destination ip address*/
/* is used to tunnel an ip datagram */
/* in ip in the case of voluntary */
/* tunneling. It is NOT a standard */
/* field in ip. */
InetT_Address tunnel_end_addr;
InetT_Address net_addr_tunneled;
void* tunnel_ptr;
double tunnel_start_time;
/* VPN Stamp time to hold the time when packet enters a VPN */
double vpn_stamp_time;
/* Mobile IP related fields */
int icmp_type;
int encap_count;
/* IPv6 extension headers container. */
IpT_Ipv6_Extension_Headers_Data* ipv6_extension_hdr_info_ptr;
/* Field to store source stat handle, Number of Hops */
Stathandle* src_num_hops_stat_hndl_ptr;
/* This field tells whether the packet has already been decrypted */
/* by a HAIPE device and is being "re-recieved" on the same interface */
Boolean haipe_processing_performed;
} IpT_Dgram_Fields;
Linux data structure defines fields in bits while simulators define them in common C data types other than bits. Since Linux, which directly runs on hardware, benefits from bit operation. But simulators cannot. So there's no need to bother fields in bits.
Comparing the structures in ns2 and OPNET, we find OPNET struture much more complex, since it supports many technologies in its IP module, including IP tunneling, MPLS, VPN, etc.
參考資料:
http://my.opera.com/Illidan/blog/ip-header-data-structure
訂閱:
意見 (Atom)